Как определить дубли страниц. Как найти дубликаты страниц на блоге WordPress? Риск попадания под фильтр ПС
Наличие внутренних дублей страниц может привести к ошибкам индексации сайта и даже свести на нет результаты продвижения. К примеру, если у продвигаемой страницы есть дубли, после очередного апдейта один из них может заменить в выдаче нужную страницу. А это обычно сопровождается существенным проседанием позиций, так как у дубля, в отличие от продвигаемой страницы, нет ссылочной массы.
Откуда берутся дубли страниц?
Как я только что упоминала, дубли бывают четкие и нечеткие.
Четкие дубли – это страницы с абсолютно одинаковым контентом, которые имеют разные URL-адреса.
Например, страница для печати и ее обычный оригинал, страницы с идентификаторами сессий, одни и те же страницы с разными расширениями (.html, .php, .htm). Большинство четких дублей генерируются движком сайта, но есть и такие, которые возникают из-за невнимательности вебмастера.
К примеру, разные URL для главной страницы – у одного нашего клиента до недавнего времени «морда» совершенно статичного сайта (без движка) была доступна по трем разным URL-адресам: site.ru/, site.ru/index.html и site.ru/default.html. Очень часто четкие дубли появляются после замены дизайна и структуры сайта – все страницы получают новые URL-адреса, но старые адреса тоже работают, и в результате каждая страница доступна по 2 разным URL.
Нечеткие дубли – это страницы с очень похожим контентом:
– где контентная часть по объему намного меньше сквозной части
: страницы галерей (где само содержание страницы состоит из одной лишь картинки, а остальное – сквозные блоки), страницы товарных позиций с описанием товара всего одним предложением и т.д..
– страницы, на которых частично (или полностью, но в разном порядке) повторяется одно и то же содержание
. Например, страницы категорий товаров в интернет-магазинах, на которых одни и те же товары отсортированы по разным показателям (по цене, по новизне, по рейтингу и т.д.) или страницы рубрик, где пересекаются одни и те же товары с одними и теми же описаниями. А также страницы поиска по сайту, страницы с анонсами новостей (если один и тот же анонс используется на нескольких страницах) и т.д.
Как определить, есть ли на сайте дубли?
Определить наличие внутренних дублей на сайте можно с помощью поиска Яндекса. Для этого в поисковой строке в расширенном поиске нужно ввести кусок текста страницы, подозреваемой в дублях (текст нужно вводить в кавычках), указав в строке «на сайте» свой домен. Все найденные страницы могут быть четкими или нечеткими дублями друг друга:
Определить дубли можно и с помощью поиска Google. Для этого нужно в поисковую строку ввести кусок текста проверяемой страницы в кавычках и через пробел указать область поиска – site:examplesite.ru. Пример запроса на проверку дублей:
“Длинное предложиение из десяти-пятнадцати слов со страницы, которую мы подозреваем в том, что у нее есть дубли и хотим подтвердить или опровергнуть это” site:examplesite.ru
Если дубли найдутся, это будет выглядеть так:
Как избавиться от дублей страниц?
Оптимальный способ избавления от дублей зависит от того, каким образом дубль появился на сайте и есть ли необходимость оставлять его в индексе (например, если это страница товарной категории или галереи).
Директива Disallow в Robots.txt
Директива “Disallow”
используется для запрещения индексации страниц поисковыми роботами и для удаления из базы уже проиндексированных страниц. Это оптимальный вариант борьбы с дублями в случаях, если дублированные страницы находятся сугубо в конкретных директориях или если структура URL позволяет закрыть много дублей одним правилом.
Например, если нужно закрыть все страницы с результатами поиска по сайту, которые находятся в папке www.examplesite.ru/search/, достаточно в Robots.txt прописать правило:
Другой пример. Если знак «?» является идентификатором сеанса, можно запретить индексацию всех страниц, содержащих этот знак, одним правилом:
Таким образом можно запрещать к индексации четкие дубли: страницы для печати, страницы идентификаторов сессий и т.д., страницы поиска по сайту и т.д.
Описание директивы «Disallow» в разделе помощи Яндекса
Описание правил блокировки и удаления страниц в справке Google
Тег rel=canonical
Тег rel=canonical
используется для того, чтоб указать роботам, какая именно страница из группы дублей должна участвовать в поиске. Такая страница называется канонической
.
Для того, чтоб указать роботам каноническую страницу, необходимо на неосновных страницах прописать ее URL:
Такой способ избавления от дублей отлично подходит в том случае, если дублей достаточно много, но закрыть их единым правилом в Robots.txt невозможно из-за особенностей URL .
301 редирект
301 Permanent Redirect используется для переадресации пользователей и поисковых ботов с одной страницы на другую. Использовать этот способ нужно в случае, если некоторые страницы в результате смены движка или структуры сайта поменяли URL, и одна и та же страница доступна и по старому, и по новому URL. 301 редирект дает сигнал поисковым ботам, что страница навсегда сменила адрес на новый, в результате чего вес cтарой страницы передается новой (в большинстве случаев).
Настроить редирект с одной страницы на другую можно, прописав в файле.htaccess такое правило:
Redirect 301 /category/old-page.html http://www.melodina.ru/category/new-page.html
Можно настроить и массовый редирект со страниц одного типа на другой, но для этого нужно, чтоб у них была одинаковая структура URL.
О том, как сделать 301 редирект на блоге Devaka.ru .
Творческий подход
Бывают случаи, когда страницы, имеющие признаки нечетких дублей, действительно содержат полезную информацию, и удалять их из индекса не хотелось бы. Что делать в таком случае? Менять, добавлять или уникализировать контент.
Например, если проблема с нечеткими дублями возникла из-за слишком объемной навигации
, нужно искать способы увеличить контентную часть или .
Часто бывает, что страницы с описаниями товаров одной и той же категории очень похожи друг на друга . Уникализировать такой текст не всегда возможно, а закрывать к индексации нецелесообразно (это уменьшает контентную часть). В этом случае можно посоветовать добавлять на страницы какие-то интересные блоки: отзывы о товаре, список отличий от других товаров и т.д.
В случае, если в разных рубриках выводится много одних и тех же товаров с одинаковыми описаниями, тоже можно применить творческий подход
. Допустим, есть интернет-магазин сумок, где одни и те же товары выводятся сразу в нескольких категориях. Например, женская кожаная сумка с ручкой от Chanel может выводиться сразу в 4-х категориях женские сумки, кожаные сумки, сумки с ручкой и сумки Chanel. В этом нет ничего плохого, так как сумка действительно подходит для всех 4-х категорий, но если анонс с описанием сумки выводится во всех этих категориях, это может навредить (особенно если пересекающихся товаров много). Выход – либо не выводить анонсы на страницах рубрик вообще, либо сокращать их до минимум и автоматически менять описания в зависимости от категорий, на которых выводится товар.
Пример: Стильная [женская] [кожаная] cумка черного цвета [с ручкой] на каждый день.
Я встречала много разных вариантов внутренних дублей на сайтах разной сложности, но не было такой проблемы, которую нельзя было бы решить . Главное, не откладывать вопрос с дублями до тех пор, когда нужные страницы начнут выпадать из индекса и сайт станет терять трафик.
Наличие дублей страниц в индексе — это такая страшная сказка, которой seo-конторы пугают обычно владельцев бизнеса. Мол, смотрите, сколько у вашего сайта дублей в Яндексе! Честно говоря, не могу предоставить примеры, когда из-за дублей сильно падал трафик. Но это лишь потому, что эту проблему я сразу решаю на начальном этапе продвижения. Как говорится, лучше перебдеть, поэтому приступим.
Что такое дубли страниц?
Дубли страниц – это копии каких-либо страниц. Если у вас есть страница site.ru/bratok.html с текстом про братков, и точно такая же страница site.ru/norma-pacany.html с таким же текстом про братков, то вторая страница будет дублем.
Могут ли дубли плохо сказаться на продвижении сайта
Могут, если у вашего сайта проблемы с краулинговым бюджетом (если он маленький).
Краулинговый бюджет — это, если выражаться просто, то, сколько максимум страниц вашего сайта может попасть в поиск. У каждого сайта свой КБ. У кого-то это 100 страниц, у кого-то — 25000.
Если в индексе будет то одна страница, то другая, в этом случае они не будут нормально получать возраст, поведенческие и другие «подклеивающиеся» к страницам факторы ранжирования. Кроме того, пользователи могут в таком случае ставить ссылки на разные страницы, и вы упустите естественное ссылочное. Наконец, дубли страниц съедают часть вашего краулингового бюджета. А это грозит тем, что они будут занимать в индексе место других, нужных страниц, и в итоге нужные вам страницы не будут находиться в поиске.
Причины возникновения дублей
Сначала вам нужно разобраться, почему на вашем сайте появляются дубли. Это можно понять по урлу, в принципе.
- Дубли могут создавать ID-сессии. Они используются для контроля за действиями пользователя или анализа информации о вещах, которые были добавлены в корзину;
- Особенности CMS (движка). В WordPress такой херни обычно нету, а вот всякие Джумлы генерируют огромное количество дублей;
- URL с параметрами зачастую приводят к неправильной реализации структуры сайтов;
- Страницы комментариев;
- Страницы для печати;
- Разница в адресе: www – не www. Даже сейчас поисковые роботы продолжают путать домены с www, а также не www. Об этом нужно позаботиться для правильной реализации ресурса.
Способы поиска дублирующего контента
Можно искать дубли программами или онлайн-сервисами. Делается это по такому алгоритму — сначала находите все страницы сайта, а потом смотрите, где совпадают Title.
XENU
XENU – это очень олдовая программа, которая издавна используется сеошниками для сканирования сайта. Лично мне её старый интерфейс не нравится, хотя задачи свои она в принципе решает. На этом видео парень ищет дубли именно при помощи XENU:
Screaming Frog
Я лично пользуюсь либо Screaming Frog SEO Spider, либо Comparser. «Лягушка» — мощный инструмент, в котором огромное количество функций для анализа сайта.
Comparser
Comparser – это все-таки мой выбор. Он позволяет проводить сканирование не только сайта, но и выдачи. То есть ни один сканер вам не покажет дубли, которые есть в выдаче, но которых уже нет на сайте. Сделать это может только Компарсер.
Поисковая выдача
Можно также и ввести запрос вида site:vashsite.ru в выдачу поисковика и смотреть дубли по нему. Но это довольно геморройно и не дает полной информации. Не советую искать дубли таким способом.
Онлайн-сервисы
Чтобы проверить сайт на дубли, можно использовать и онлайн-сервисы.
Google Webmaster
Обычно в панели вебмастера Google, если зайти в «Вид в поиске — Оптимизация HTML», есть информация о страницах с повторяющимся метаописанием. Так можно найти часть дублей. Вот видеоинструкция:
Sitereport
Аудит сайта от сервиса Sitereport также поможет найти дубли, помимо всего прочего. Хотя дублированные страницы можно найти и более простыми/менее затратными способами.
Решение проблемы
Для нового и старого сайта решения проблемы с дублями — разные. На новом нам нужно скорее предупредить проблему, провести профилактику (и это, я считаю, самое лучшее). А на старом уже нужно лечение.
На новом сайте делаем вот что:
- Сначала нужно правильно настроить ЧПУ для всего ресурса, понимая, что любые ссылки с GET-параметрами нежелательны;
- Настроить редирект сайта с www на без www или наоборот (тут уж на ваш вкус) и выбрать главное зеркало в инструментах вебмастера Яндекс и Google;
- Настраиваем другие редиректы — со страниц без слеша на страницы со слешем или наоборот;
- Завершающий этап – это обновление карты сайта.
Отдельное направление – работа с уже имеющимся, старым сайтом:
- Сканируем сайт и все его страницы в поисковых системах;
- Выявляем дубли;
- Устраняем причину возникновения дублей;
- Проставляем 301 редирект и rel=»canonical» с дублей на основные документы;
- В обязательном порядке 301 редиректы ставятся на страницы со слешем или без него. Обязательная задача – все url должны выглядеть одинаково;
- Правим роботс — закрываем дубли, указываем директиву Host для Yandex с заданием основного зеркала;
- Ждем учета изменений в поисковиках.
Поисковые алгоритмы постоянно развиваются, часто уже сами могут определить дубли страницы и не включать такие документы в основной поиск. Тем не менее, проводя экспертизы сайтов, мы постоянно сталкиваемся с тем, что в определении дублей алгоритмы еще далеки от совершенства.
Что такое дубли страниц?
Дубли страниц на сайте – это страницы, контент которых полностью или частично совпадает с контентом другой, уже существующей в сети страницы.
Адреса таких страниц могут быть почти идентичными.
Дубли:
- с доменом, начинающимся на www и без www, например, www.site.ru и site.ru.
- со слешем в конце, например, site.ru/seo/ и site.ru/seo
- с.php или.html в конце, site.ru/seo.html и site.ru/seo.php
Одна и та же страница, имеющая несколько адресов с указанными отличиями восприниматься как несколько разных страниц – дублей по отношению друг к другу.
Какими бывают дубликаты?
Перед тем, как начать процесс поиска дублей страниц сайта, нужно определиться с тем, что они бывают 2-х типов, а значит, процесс поиска и борьбы с ними будет несколько отличным. Так, в частности, выделяют:
- Полные дубли - когда одна и та же страница размещена по 2-м и более адресам.
- Частичные дубли - когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
Причины возникновения дублей
Сначала вам нужно разобраться, почему на вашем сайте появляются дубли. Это можно понять по урлу, в принципе.
- Дубли могут создавать ID-сессии. Они используются для контроля за действиями пользователя или анализа информации о вещах, которые были добавлены в корзину;
- Особенности CMS (движка). В WordPress обычно дублей страниц нет, а вот Joomla генерирует огромное количество дублей;
- URL с параметрами зачастую приводят к неправильной реализации структуры сайтов;
- Страницы комментариев;
- Страницы для печати;
- Разница в адресе: www – не www. Даже сейчас поисковые роботы продолжают путать домены с www, а также не www. Об этом нужно позаботиться для правильной реализации ресурса.
Влияние дублей на продвижение сайта
- Дубли нежелательны с точки зрения SEO, поскольку поисковые системы накладывают на такие сайты санкции, отправляют их в фильтры, в результате чего понижается рейтинг страниц и всего сайта вплоть до изъятия из поисковой выдачи.
- Дубли мешают продвижению контента страницы, влияя на релевантность продвигаемых страниц. Если одинаковых страниц несколько, то поисковику непонятно, какую из них нужно продвигать, в результате ни одна из них не оказывается на высокой позиции в выдаче.
- Дубли снижают уникальность контента сайта: она распыляется между всеми дублями. Несмотря на уникальность содержания, поисковик воспринимает вторую страницу неуникальной по отношении к первой, снижает рейтинг второй, что сказывается на ранжировании (сортировка сайтов для поисковой выдачи).
- За счет дублей теряется вес основных продвигаемых страниц: он делится между всеми эквивалентными.
- Поисковые роботы тратят больше времени на индексацию всех страниц сайта, индексируя дубли.
Как найти дубли страниц
Исходя из принципа работы поисковых систем, становится понятно, что одной странице должна соответствовать только одна ссылка, а одна информация должна быть только на одной странице сайта. Тогда будут благоприятные условия для продвижения нужных страниц, а поисковики смогут адекватно оценить ваш контент. Для этого дубли нужно найти и устранить.
Программа XENU (полностью бесплатно)
Программа Xenu Link Sleuth (http://home.snafu.de/tilman/xenulink.html), работает независимо от онлайн сервисов, на всех сайтах, в том числе, на сайтах которые не проиндексированы поисковиками. Также с её помощью можно проверять сайты, у которых нет накопленной статистики в инструментах вебмастеров.
Поиск дублей осуществляется после сканирования сайта программой XENU по повторяющимся заголовкам и метаописаниям.
Программа Screaming Frog SEO Spider (частично бесплатна)

Адрес программы https://www.screamingfrog.co.uk/seo-spider/ . Это программа работает также как XENU, но более красочно. Программа сканирует до 500 ссылок сайта бесплатно, более объемная проверка требует платной подписки. Сам ей пользуюсь.
Программа Netpeak Spider (платная с триалом)

Яндекс Вебмастер
Для поиска дублей можно использовать Яндекс.Вебмастер после набора статистики по сайту. В инструментах аккаунта на вкладке Индексирование > Страницы в поиске можно посмотреть «Исключенные страницы» и выяснить причину их удаления из индекса. Одна из причин удаления это дублирование контента. Вся информация доступна под каждым адресом страницы.

Google Search Console
В консоли веб-мастера Google тоже есть инструмент поиска дублей. Откройте свой сайт в консоли Гугл вебмастер. На вкладке Вид в поиске > Оптимизация HTML вы увидите, если есть, повторяющиеся заголовки и метаописания. Вероятнее всего это дубли (частичные или полные).

Язык поисковых запросов
Используя язык поисковых запросов можно вывести список всех страниц сайта, которые есть в выдаче (оператор «site:» в Google и Yandex) и поискать дубли «глазами».

Сервисы онлайн
Есть сервисы, который проверяют дубли страниц на сайте онлайн. Например, сервис Siteliner.com (http://www.siteliner.com/). На нём можно найти битые ссылки и дубли. Можно проверить до 25000 страниц по подписке и 250 страниц бесплатно.

Российский сервис Saitreport.ru, может помочь в поиске дублей. Адрес сервиса: https://saitreport.ru/poisk-dublej-stranic

Удаление дублей страниц сайта
Способов борьбы с дубликатами не так уж и много, но все они потребуют от вас привлечения специалистов-разработчиков, либо наличия соответствующих знаний. По факту же арсенал для «выкорчевывания» дублей сводится к:
- Их физическому удалению - хорошее решение для статических дублей.
- Запрещению индексации дублей в - подходит для борьбы со служебными страницами, частично дублирующими контент основных посадочных.
- в файле-конфигураторе «.htaccess» - хорошее решение для случая с рефф-метками и ошибками в иерархии URL.
- Установке тега « » - лучший вариант для страниц пагинации, фильтров и сортировок, utm-страниц.
- Установке тега «meta name=»robots» content=»noindex, nofollow»» - решение для печатных версий, табов с отзывами на товарах.
Чек-лист по дублям страниц
Часто решение проблемы кроется в настройке самого движка, а потому основной задачей оптимизатора является не столько устранение, сколько выявление полного списка частичных и полных дублей и постановке грамотного ТЗ исполнителю.
Запомните следующее:
- Полные дубли - это когда одна и та же страница размещена по 2-м и более адресам. Частичные дубли - это когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
- Полные и частичные дубли могут понизить позиции сайта в выдаче не только в масштабах URL, а и всего домена.
- Полные дубликаты не трудно найти и устранить. Чаще всего причина их появления зависит от особенностей CMS сайта и навыков SEO разработчика сайта.
- Частичные дубликаты найти сложнее и они не приводят к резким потерям в ранжировании, однако делают это постепенно и незаметно для владельца сайта.
- Чтобы найти частичные и полные дубли страниц, можно использовать мониторинг выдачи с помощью поисковых операторов, специальные программы-парсеры, поисковую консоль Google и ручной поиск на сайте.
- Избавление сайта от дублей сводится к их физическому удалению, запрещению индексации дублей в файле «robots.txt», настройке 301 редиректов, установке тегов «rel=canonical» и «meta name=»robots» content=»noindex, nofollow»».
Сегодня мы поговорим о дублях. А именно - что такое дубли страниц на сайте, чем они грозят продвижению, как их найти и убрать.
Что такое дубли страниц на сайте?
Дубли - это страницы с частично или полностью совпадающим контентом, но доступные по разным URL-адресам. Принято их классифицировать как четкие и нечеткие. Примером четких могут послужить зеркала главной страницы сайта:
site.ru
www.site.ru
site.ru/index.php
А нечетких - большие сквозные для всего ресурса участки текста:
Чем опасны дубли страниц?
1. Перескоки релевантных страниц в поисковой выдаче. Самая распространенная проблема, заключающаяся в том, что поисковая система не может однозначно определить, какой из документов следует показывать в выдаче по запросу, тематике которого они удовлетворяют. Как итог - broser rank и поведенческая информация размазываются по дублям, позиции постоянно скачут и далеко не в положительную сторону.
2. Снижение уникальности контента сайта. Ну, тут всё очевидно - идет снижение процента страниц с уникальным контентом, что не может не оказывать негативного влияния на его ранжирование.
Откуда берутся дубли страниц?
1. CMS. Очень популярная причина, берущая своё начало в несовершенстве работы используемой системы управления. Тривиальная ситуация для примера - когда одна запись на сайте принадлежит к нескольким категориям, чьи алиасы входят в URL самой записи. В итоге мы получаем откровенные дубли, например:
site.ru/category1/post/
site.ru/category2/post/
2. Служебные разделы. Тоже можно отнести к несовершенству функционирования CMS, но из-за распространенности проблемы, выношу её в отдельный пункт. Особенно тут грешат Joomla и Birix. Например, какая-либо функция на сайте (авторизация, фильтрация, поиск и т.д.) плодит параметрические адреса, имеющие идентичный контент относительно страницы без параметров в урле. Например:
site.ru/page.php
site.ru/page.php?ajax=Y
3. Человеческий фактор. Сюда можно отнести всё то, что является порождением рук человеческих:
- Упомянутые ранее большие сквозные участки текста.
- Сквозные статические блоки.
- Банальное дублирование статей.
По второму пункту хотелось бы уточнить, что тут речь тут идет в первую очередь про код. На этот счет идет много дебатов, но я говорю абсолютно точно - большие участки сквозного кода - очень плохо. У меня минимум 3 кейса в практике было, когда сокрытие от роботов сквозняков увеличивало индексацию сайта с 20 до 60 тысяч страниц в течении всего одного-двух месяцев. Но тут банального
4. Технические ошибки. Что-то среднее между несовершенством работы CMS и человеческим фактором. Первый пример, который приходит в голову, имел место быть на системе Opencart, когда криво поставленная ссылка привела к зацикливанию:
site.ru/page/page/page/page/../..
Как найти дубли страниц на сайте?
Легче и надежнее всего это будет сделать, пройдя следующие 3 этапа.
1. Программная проверка сайта на дубли страниц. Берем NetPeak Spider, Screaming Frog SEO Spider или любую другую из подобных софтин для внутреннего анализа и сканируем сайт. Затем сортируем, например, по метазаголовкам, и обращаем внимание на их совпадение или полное отсутствие. Совпадение - повод для проверки этих страниц вручную, а отсутствие метаинформации - один из вероятных признаков технического раздела, который лучше закрыть от индексации.

2. 301 редирект. Этот вариант подойдет вам, если копии носят точечный характер и вы не хотите их закрывать от индексации по той или иной причине (например, на них уже кто-то успел поставить внешнюю ссылку). В таком случае просто настраиваем 301 редирект с дубля на основную страницу и проблема решена.
3. Link rel="canonical".
Это является неплохим решением для описанной выше ситуации, когда один и тот же пост доступен по разным урлам. Для каждого такого поста внедряется в код тег вида
Данный тег программно внедряется для каждого поста и далее пусть у него будет хоть 100 урлов - на всех них в коде будет рекомендация для поисковой системы, какой урл вы советуете индексировать, а на какие не обращать внимания (на страницы, чей собственный url и url в link rel="canonical" не совпадают).
4. Google Search Console. Малопопулярный, но, тем не менее, работающий приём, к которому мы можем обратиться в разделе «Сканирование» - «Параметры URL» из Google Search Console.

Добавляя параметры в эту таблицу, мы можем сообщить поисковому роботу, что страницы ними никак не изменяют содержимого, а потому их можно не индексировать. Но, конечно, возможны и другие варианты, при которых содержимое раздела при включении параметра в адрес «перемешивается», оставаясь, однако, при этом неизменным по своему составу (например, сортировка по популярности записей в категории).
Указав об этом в данном разделе, мы тем самым поможем Google лучше интерпретировать сайт в процессе его сканирования. Сообщив о предназначении параметра в URL, вопрос об индексации таких страниц лучше оставить «На усмотрение робота Googlebot&rauqo;.

Часто задаваемые вопросы
Многостраничные разделы (пагинация) - дубли или нет? Закрывать ли от индексации?
Нет, не нужно их закрывать ни от индексации, ни ставить rel="canonical" на первую страницу раздела, так как они имеют уникальный относительно друг-друга контент, а потому не являются дублями. Поисковые системы прекрасно умеют распознавать пагинацию, ну а для пущей надежности достаточно будет снабдить их элементами микроразметки rel="next" и rel="prev". Например:
Урлы с хештегами (#) - дубли или нет? Удалять ли их?
Нет. Поисковая система по умолчанию не индексирует страницы с # в адресе, так что по этому поводу волноваться не надо.
Вот, наверно, и всё. Вопросы?
Доброго времени суток!
Дубликаты страниц , или дубли — одна из тех проблем, о которой не подозревают многие вебмастера. Из-за такой ошибки, некоторые полезные WordPress-блоги теряют позиции по ряду запросов, и порою их владельцы даже не догадываются об этом. Каждый видит в статистике, что посещаемость веб-страницы упала, но разыскать и исправить ошибку могут не все. В этой статье пойдет речь о том, как найти дубли страниц сайта.
Что такое дубликаты страниц?
Дубли – это две и больше страниц с одинаковым контентом, но разными адресами. Существует понятие полных и частичных дублей. Если полные — это стопроцентный дублированный контент исходной (канонической ) страницы, то частичным дублем может стать страница, повторяющая ее отдельные элементы. Причины появления дублей могут быть разными. Это могут быть ошибки вебмастера при составлении или изменении шаблона сайта. Но чаще всего дубли возникают автоматически из-за специфики работы движков, таких как WordPress и Joomla. О том, почему это происходит, и как с этим справляться я расскажу ниже. Очень важно понимать, что вебсайты с такими повторениями могут попасть под и понижаться в выдаче, поэтому дублей стоит избегать.
Как проверить сайт на дубли страниц?
Практика показывает, что отечественный поисковик Яндекс относится к дублям не так строго, как зарубежный Гугл. Однако и он не оставляет такие ошибки вебмастеров без внимания, поэтому для начала нужно разобраться с тем, как найти дубликаты страниц.
Во-первых, нам нужно определить, какое количество страниц нашего сайта находится в индексе поисковых систем. Для этого воспользуемся функцией site:my-site.ru, где вместо my-site.ru вам нужно подставить свой url. Покажу, как это работает на примере своего блога. Начнем с Яндекса. Вводим в строку поиска site:сайт

Как видим, Яндекс нашел 196 проиндексированных страниц. Теперь проделаем то же самое с Google.

Мы получили 1400 страниц в общем индексе Гугл. Кроме основных страниц, участвующих в ранжировании, сюда попадают так называемые «сопли». Это дубли, либо малозначимые страницы. Чтобы проверить основной индекс в Google, нужно ввести другой оператор: site:сайт/&

Итого в основном индексе 165 страниц. Как видим, у моего блога есть проблема с количеством дублей. Чтобы их увидеть, нужно перейти на последнюю страницу общей выдачи и нажать «показать скрытые результаты ».

Снова перейдя в конец выдачи, вы увидите примерно такое:

Это и есть те самые дубли, в данном случае replycom . Такой тип дублей в WordPress создается при появлении комментариев на странице. Есть множество разных видов дублей, их названия и способы борьбы с ними, будут описаны в следующей статье.
Наверняка у вас возник вопрос, почему в Яндексе мы не увидели такого количества дублей, как в Google. Все дело в том, что в файле robots.txt (кто не знает что это, читайте « ») на блоге стоит запрет на индексацию подобных дублей с помощью директивы Disallow (подробнее об этом в следующем посте). Для Яндекса этого достаточно, но Гугл работает по своим алгоритмам и все равно учитывает эти страницы. Но их контент он не показывает, говорит, что «Описание веб-страницы недоступно из-за ограничений в файле robots.txt».
Проверка на дубли страниц по отрывку текста, по категориям дублей
Кроме вышеописанного способа, вы можете проверять отдельные страницы сайта на наличие дублей. Для этого в окне поиска Яндекс и Google, можно указать отрывок текста страницы, после которого употребить все тот же site:my-site.ru. Например, такой текст с одной из моих страничек: «Eye Dropper - это дополнение позволяет быстро узнать цвет элемента, чем-то напоминает пипетку в Photoshop». Его вставляем в поиск Гугл, а после через пробел site:my-site

Google не нашел дублей это страницы. Для Яндекса проделываем то же самое, только текст страницы берем в кавычки «».
Кроме фрагментов текста, вы можете вставлять ключевые фразы, по которым, к примеру, у вас снизились позиции.
Есть другой вариант такой же проверки через расширенный поиск. Для Яндекса — yandex.ru/advanced.html .
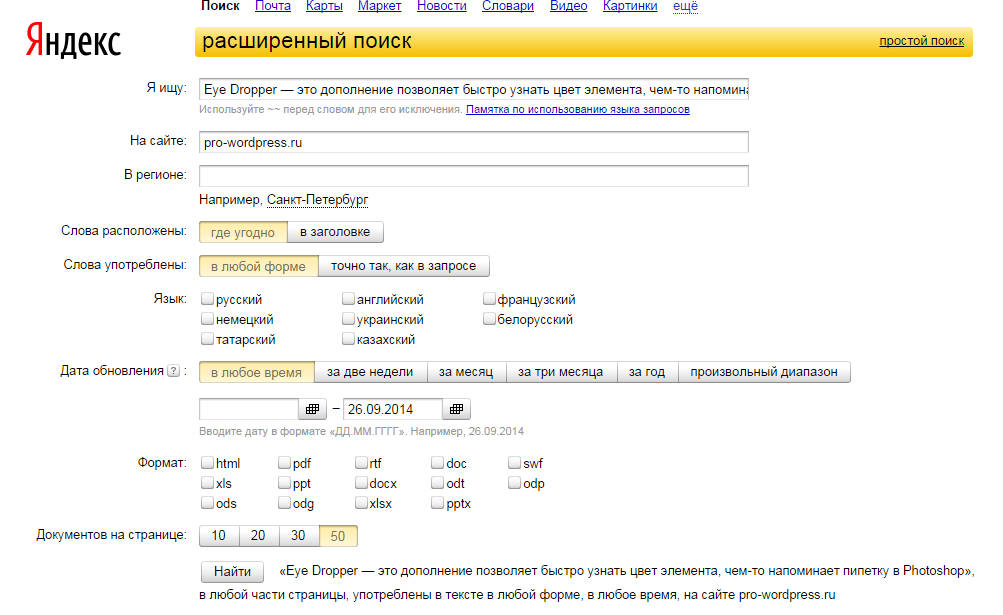
Вводим тот же текст, url сайта и жмем «Найти ». Получим такой же результат, как и с оператором site:my-site .
Либо такой поиск можно осуществить, нажав кнопку настроек в правой части окна Яндекс.
Для Гугла есть такая же функция расширенного поиска.

Теперь посмотрим, как можно выявить группу дублей одной категории. Возьмем, к примеру, группу tag.

И увидим на странице выдачи по данному запросу следующее:

А если попросить Гугл вывести скрытые результаты, дублей группы tag станет больше.
Как вы успели заметить, дубликатов страниц создается очень много и наша задача – предотвратить их попадание в индекс поисковиков.
Поиск дублей страниц сайта: дополнительные способы
Кроме ручных способов, есть также возможность автоматически проверить сайт на дубли страниц.
Например, это программа Xenu , предназначенная для технического аудита сайта. Кроме дубликатов страниц, она выявляет . Это не единственная программа для решения таких задач, но наиболее распространенная.
Также в поиске дублей страниц помогает Google Webmaster, здесь можно выявить страницы с повторяющимися мета-тегами:

Тут вы посмотрите список урлов с одинаковыми тайтлами или описанием. Часть из них может оказаться дублями.
На сегодня все. Теперь вы знаете, как найти дубликаты страниц. В мы подробно разберем, как предотвратить их появление и удалить имеющиеся дубли.